Once per year at SME Water we each take on an ‘Assignment’. This is a research project undertaken in our learning and development time to further our skills in an area of interest. In this blog, I’ll share some of what I’ve learned and achieved this year while developing a distributed computing system to help us run Sonar’s acoustic analysis faster.
Project Octo-snap and parallel computing
Introduction
Motivation

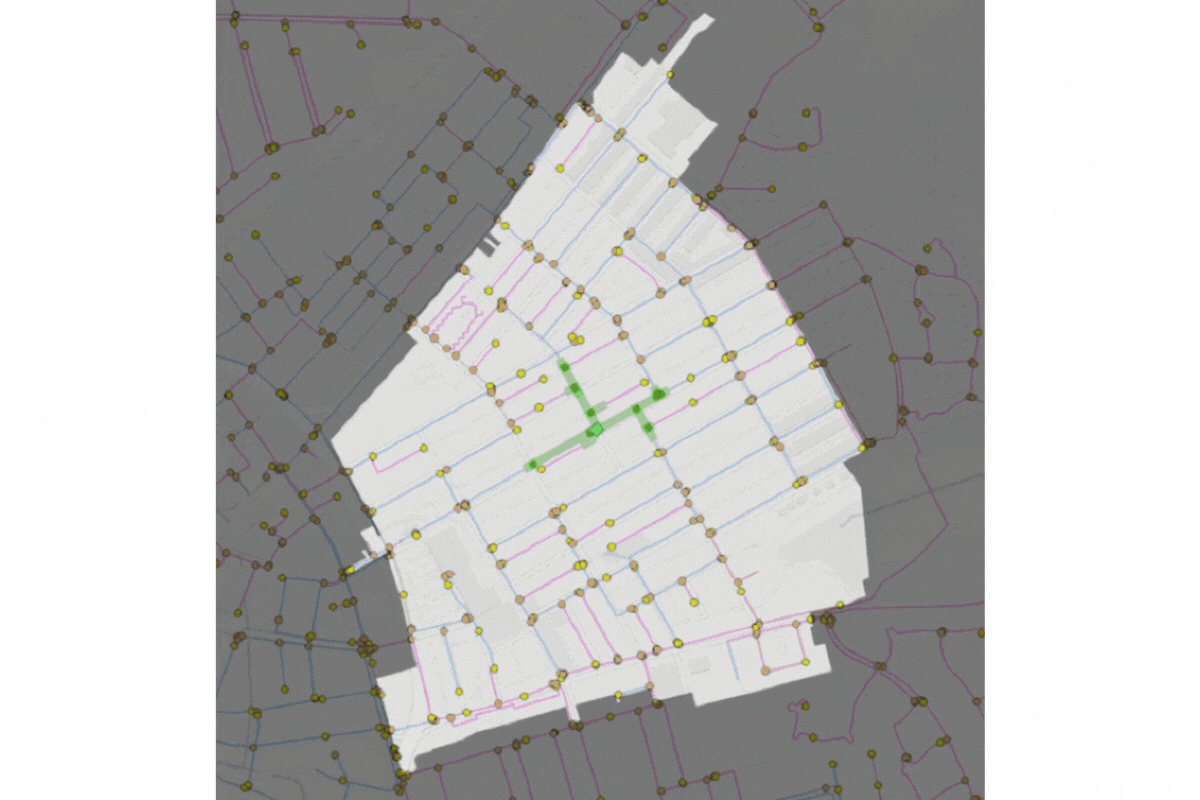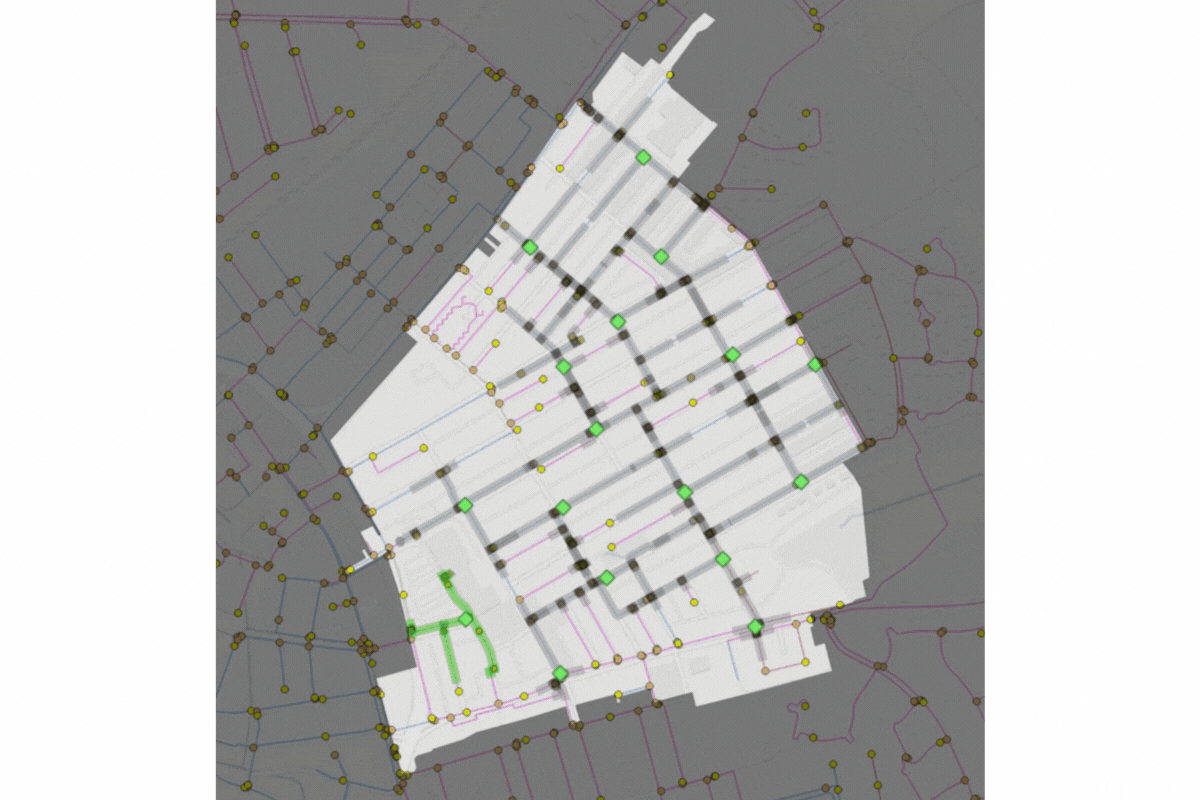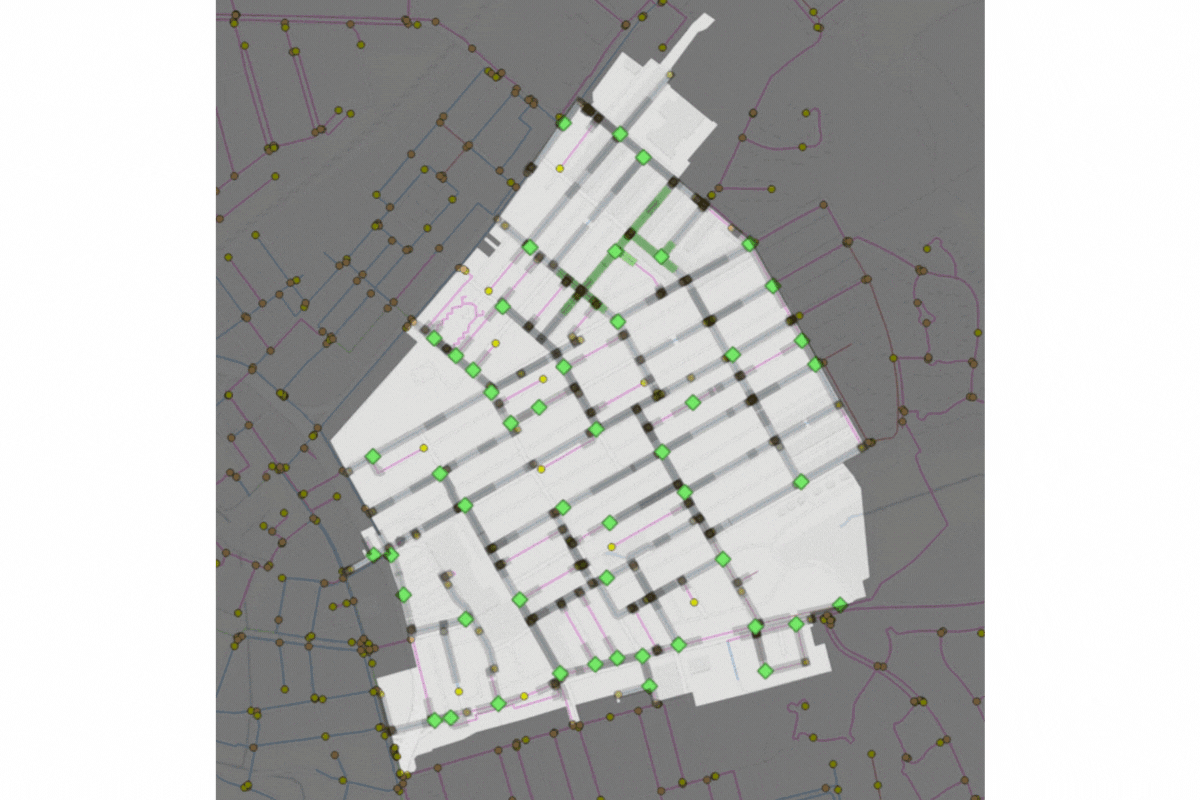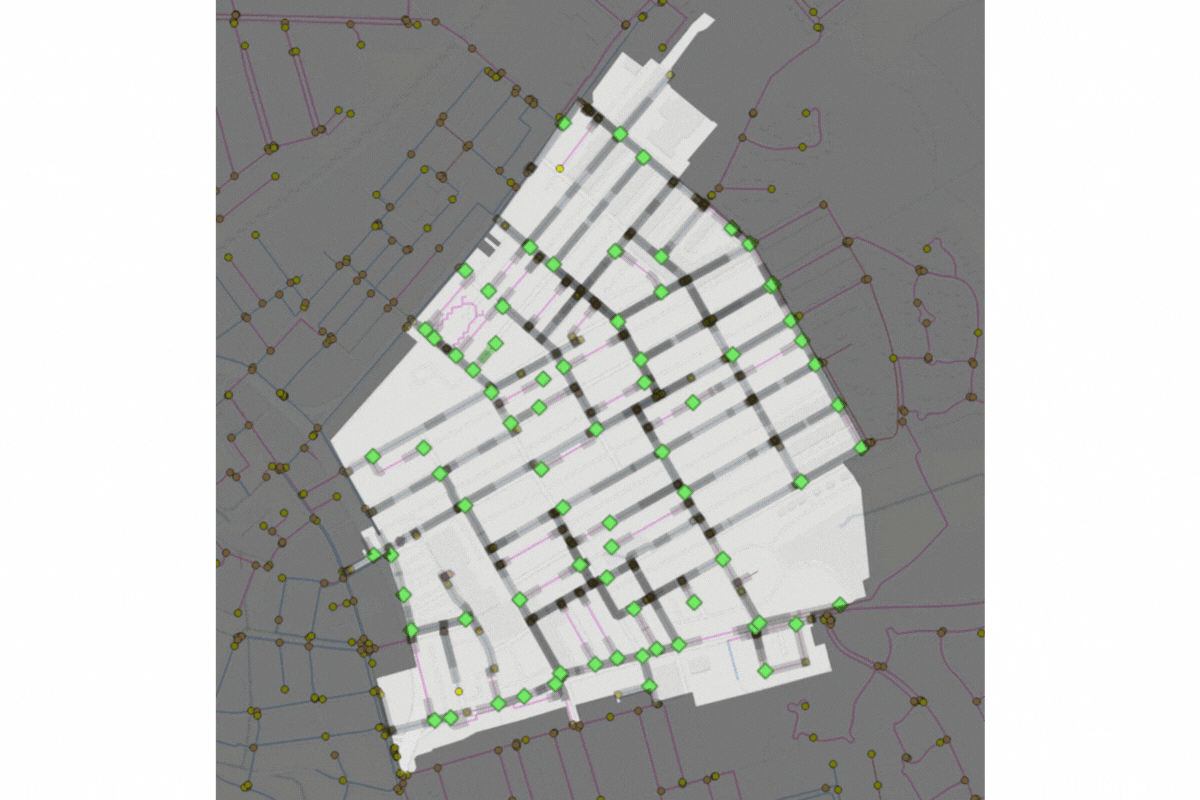
Figure 1 – Acoustic deployment optimisation
A lot has changed since my previous blog, with the acoustic noise logger deployment optimiser maturing and now forming part of our acoustic analysis suite, Sonar (Figure 1). Its insights are already helping water companies make savings, but a lot of heavy spatial computations are required to reach an optimised solution. As a business, we face a challenge in delivering these insights to our clients as fast as possible. With diminishing returns from optimising the code, I saw an opportunity to pursue my interest in distributed/parallel computing to help improve performance and got to work.
Aims & Objectives
The primary aims of this project were:
- Design and implement a system to parallelise spatial analysis across multiple computers
- Demonstrate the performance benefit
- Learn (& document) how to set up a Linux server
To achieve these goals, I had an approach in mind which would take advantage of some nice features of Python and PostgreSQL, fitting in nicely with our existing tech stack.
Design
To help inform the design approach, several observations were important:
- Sonar optimises DMAs one at a time, with each taking several minutes (or longer for large areas)
- No communication is required between the analysis of any two DMAs
- Most of the optimiser run time is spent waiting for spatial database queries to return results
These observations led me to a simple idea: running two database servers should be about twice as fast. Each could handle analysing one DMA at a time, writing the results to some shared location. And if we can use two, why not more? Of course, I’d rather not physically run around between multiple computers to make this happen. So, I devised an architecture where one computer would be the “master” and would coordinate a pool of workers to ensure they were kept busy analysing a queue of DMAs.
I also had to consider how to efficiently set up each worker for analysis. Simply copying the entire Sonar solution on to multiple computers would be wasteful, as a lot of the functionality (and data) is not required for the spatial query which we want to parallelise. In the next section, I’ll talk about the architecture I came up with to get around this, and the technology used to implement it.
Implementation
The diagram in Figure 2 gives a high-level overview of how the required data is served from the master server to the workers. The grey box on the left side represents the master, where raw data is transformed into a standard schema ready for analysis. The system uses PostgreSQL’s logical replication features to “publish” these tables to the worker nodes, each one of which has a “subscription” to the master. With this mechanism, after initial setup there will be no further action required to load data into a worker. The replication process will continuously ensure that the workers stay synced to the master, propagating any data changes as they occur.
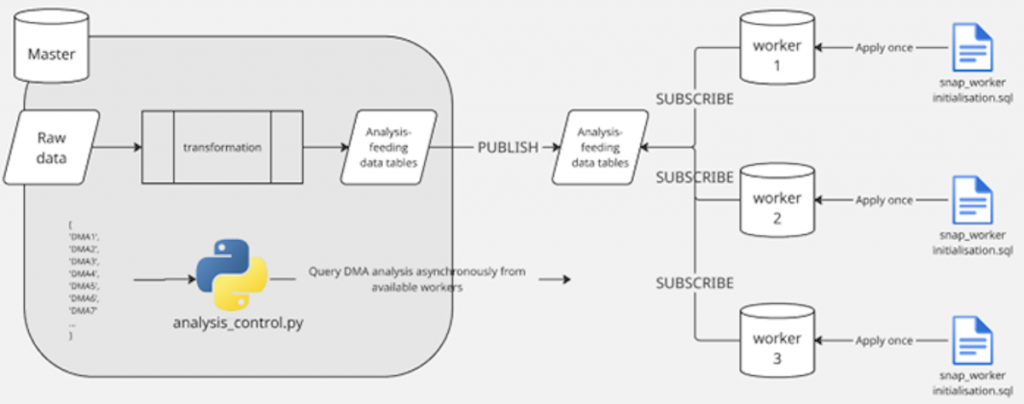
Figure 2 – System overview
One of the key requirements for this system was easy scalability. This has been ensured by using a single script for all worker configuration. This handles the creation of input and output tables, all required functions and the subscription to sync the input data from the master.
The analysis is controlled by a Python script running on the master server. This utilises the asyncio library to assign tasks from an input queue to each of the workers, handle any intermittent connection issues and collate the results back into one place. I have promised not to show any code in this blog, so let’s move on and see if it worked!
Results
To facilitate speedy development, I initially tested the system with a subset of small DMAs in which maximum coverage could be achieved with around 15 loggers. To help visualise the parallelisation and the speed up, each run outputs a timeline plot (Figure 3). Time runs along the x-axis, with each row representing one of 4 computers working in parallel. Each coloured bar represents the optimisation analysis for one DMA in the test set.
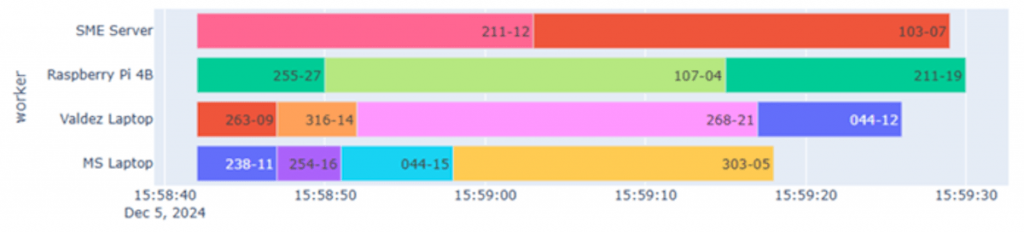
Figure 3 – Timeline of test run
After some learning and several code revisions, the computers were working in parallel. I was able to use timelines to verify that with 4 workers, the analysis of all DMAs in the set was completed approximately 4 times as fast as with a single worker.
One of the workers (Raspberry Pi 4B) ran a Linux operating system. One advantage was that this allowed me to not only configure the worker database server in a single script, but to also absorb everything besides the operating system installation (e.g., PostgreSQL installation and initialisation, firewall and networking rules) into a single script thanks to the command-line driven nature of Linux systems. I was happy to get the opportunity to gain experience in this area, as it opens further possibilities for us to leverage clusters of Linux servers for our computing infrastructure needs.
Use in Production
Since the completion of my assignment project, the octo-snap system has seen use in delivering results to our clients. We recently provided optimised logger deployment plans for the entire of Southern Water’s distribution network, as part of our collaboration with Dayworth Consulting to support their DMA leakage management playbook. This involved the analysis of over 1300 DMAs, and by using the system described in this blog we were able to deliver the results one week sooner than if the analysis has been run on a single server (Figure 4).
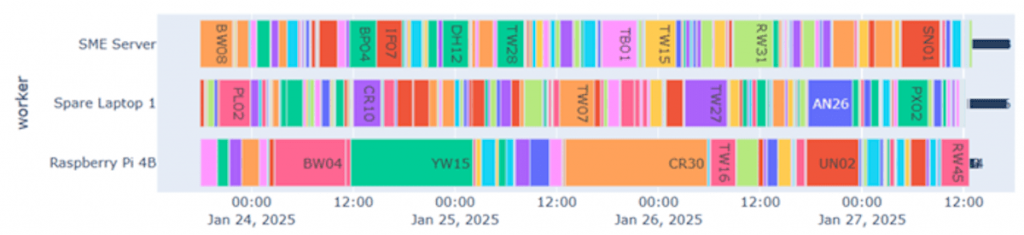
Figure 4 – Production timeline
Final Thoughts
It’s an exciting time here at SME Water as we launch our Sonar acoustic analysis platform. I was very pleased with the outcome of this year’s assignment project, which was a great opportunity to advance my software development skills by delivering something which adds value to our products. I look forward to learning more by continuing to apply myself to interesting problems over the coming year.
