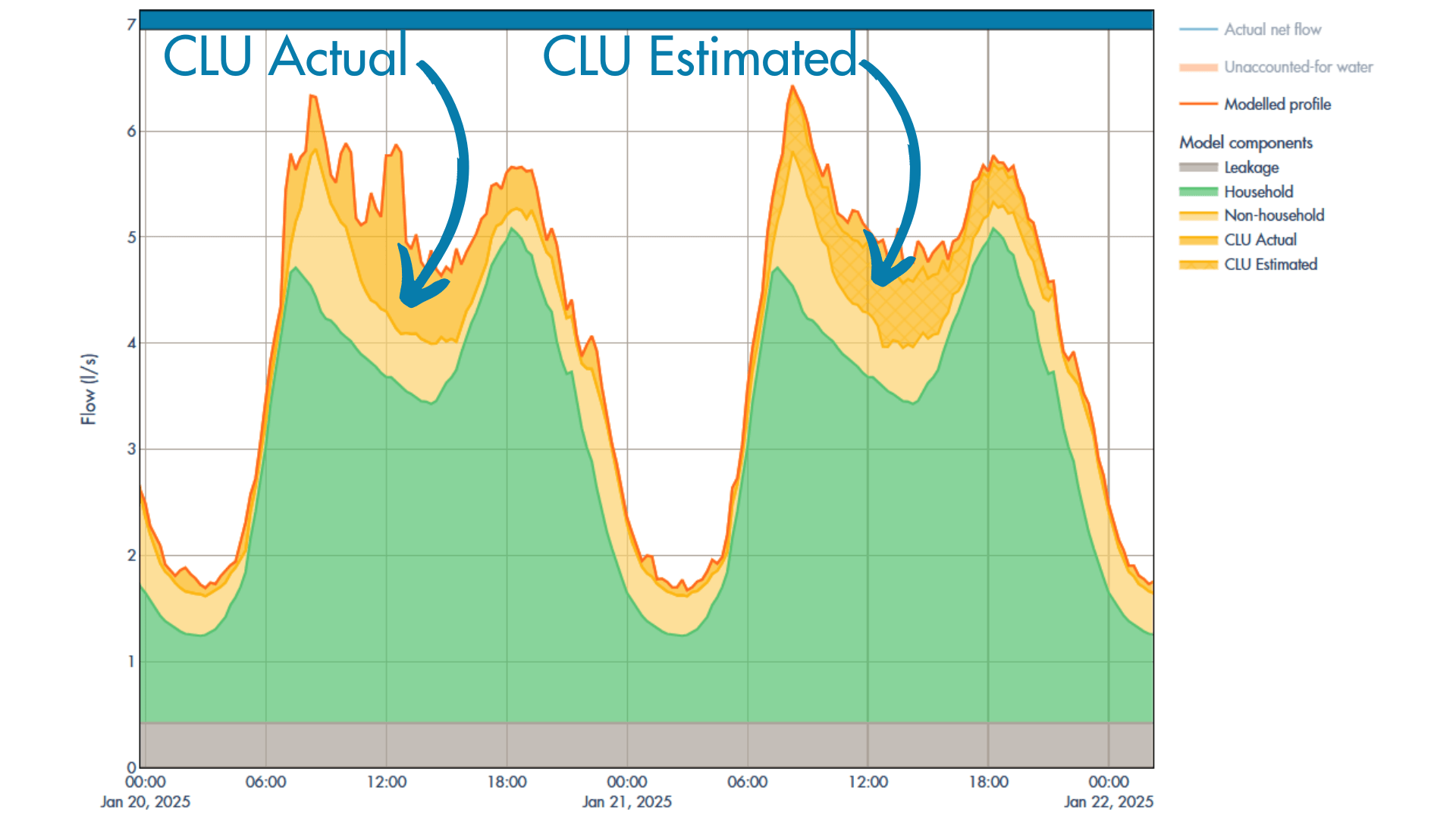
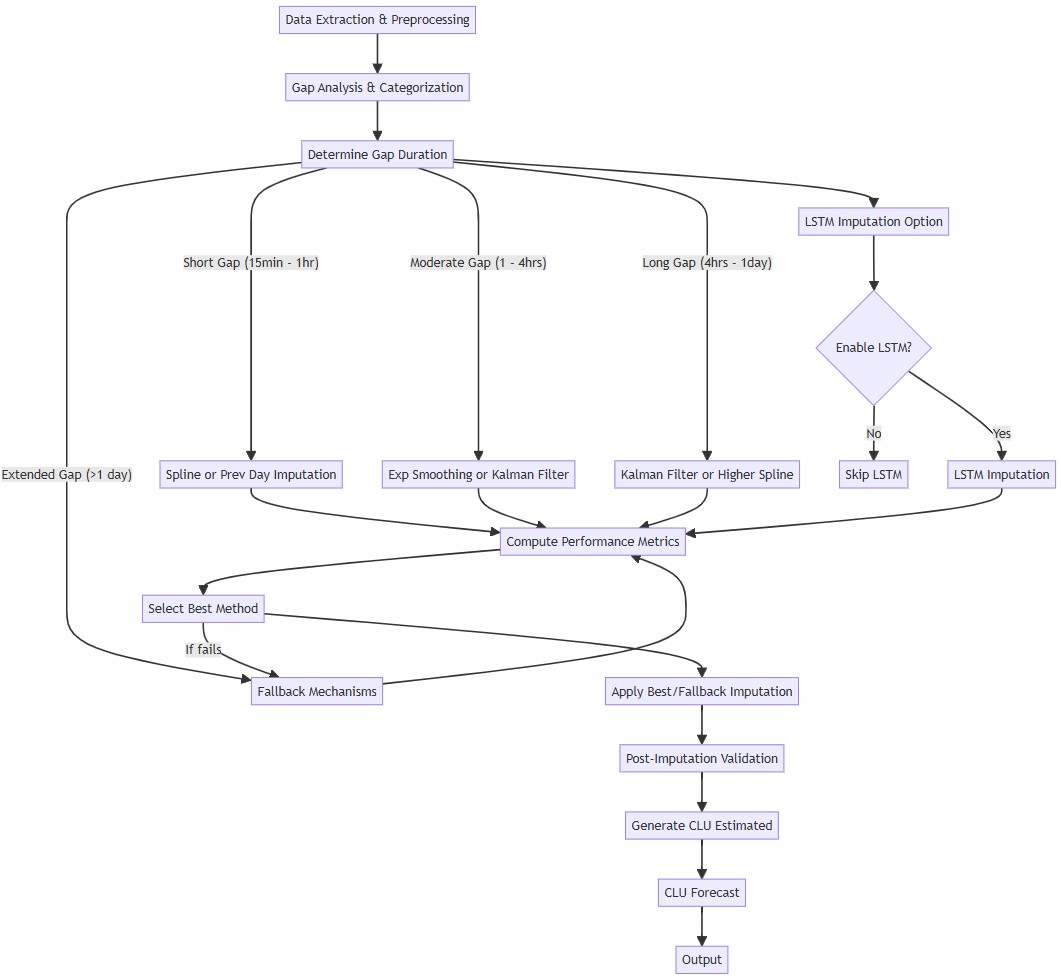
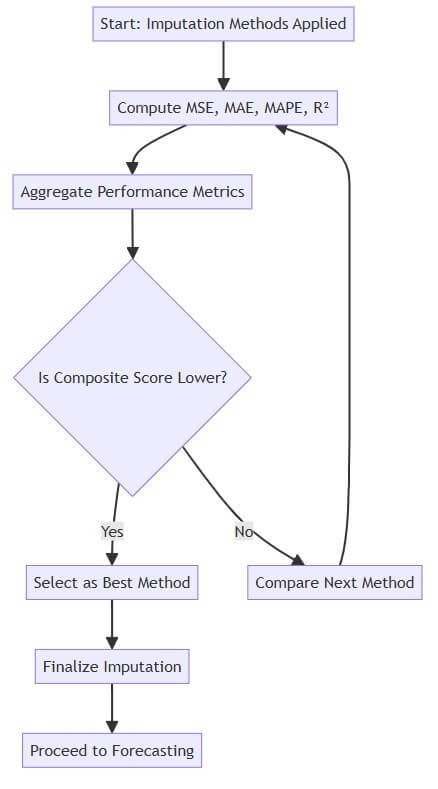
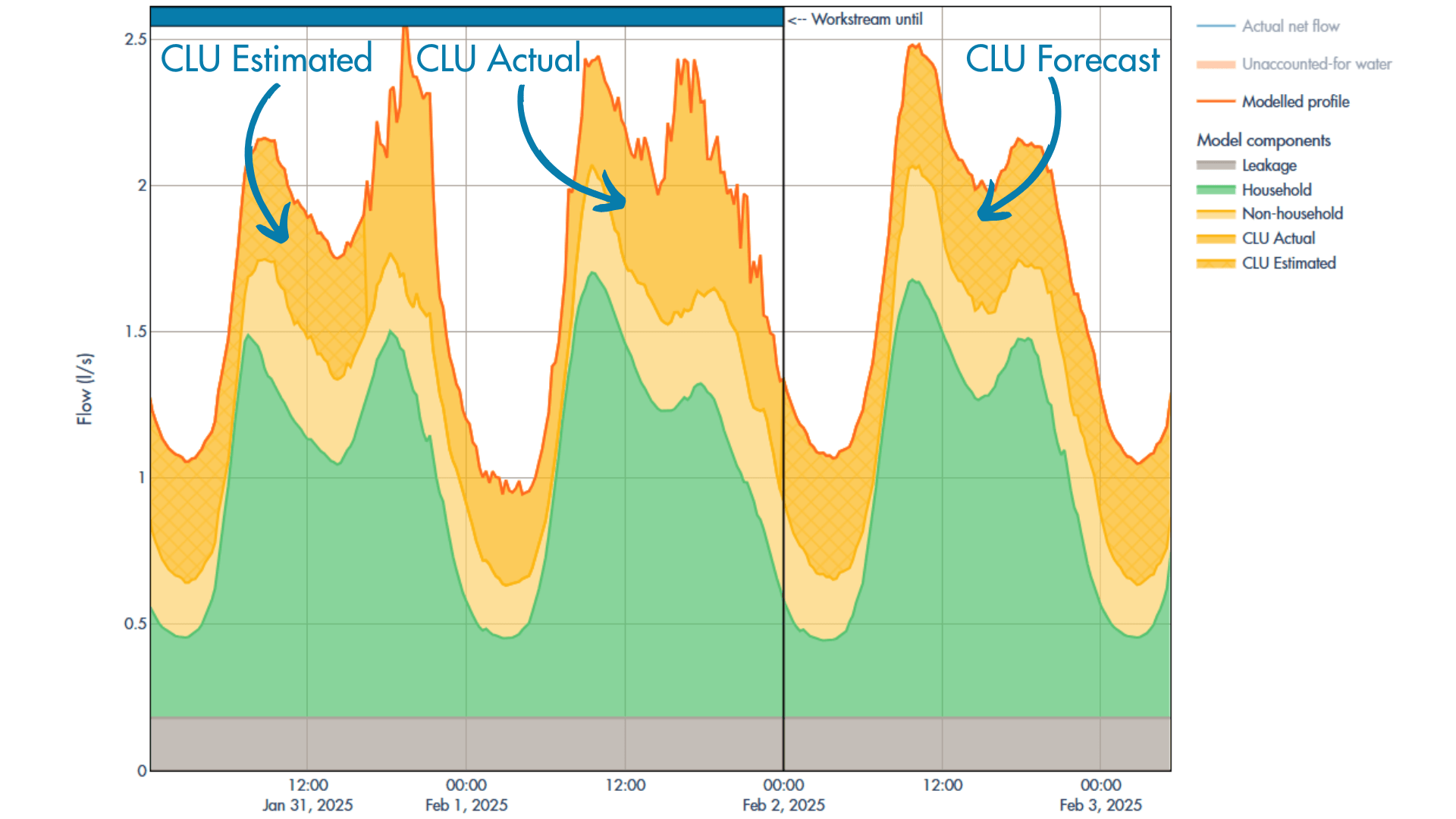
The core of the approach lies in the implementation of multiple imputation algorithms, each suited to handle different types of missing data gaps and data characteristics identified during the gap analysis. The following methods are integral to this strategy:
• Kalman Filter Imputation:
This method treats the time series as a dynamic system, starting out with initial estimates, and then continuously updating these estimates as new information becomes available, allowing us to capture underlying patterns and trends over time. The Kalman Filter begins by initially filling missing values using forward padding to provide a baseline. It is then initialized with parameters derived from the CLU data’s mean and variance. Through an iterative optimization technique called Expectation-Maximization (EM) steps, the filter refines its estimates, smoothing out noise and predicting missing values. Post-imputation validation is in place to make sure that no residual anomalies or unrealistic values persist.
• Exponential Smoothing Imputation
This approach is a forecasting technique that applies weighted averages of past observations, with weights decreasing exponentially over time. This method excels in capturing trends and seasonal patterns within the data, making it suitable for imputing missing values in datasets exhibiting such characteristics. After an initial interpolation to address minor gaps, the Exponential Smoothing model is configured with additive components for trend and seasonality. In this additive framework, the trend components assume linear progression over time, adding a constant increment while the seasonal component captures recurring fluctuations by adding a fixed seasonal effect to the overall level. By fitting this model to the data, it forecasts missing values as the sum of these additive components, resulting in smooth, datacentric imputation that effectively reflect underlying temporal patterns.
• Spline Interpolation Imputation
Spline Interpolation employs mathematical functions to create a smooth curve that passes through known data points. Depending on the degree of the spline—cubic or linear—this method can adapt to varying data characteristics. The process begins with interpolating small gaps to stabilize the data, then selecting an appropriate spline degree, based on the underlying trend. The chosen spline is fitted to the non-missing data points and subsequently used to estimate the missing values. Validation steps are in place to make sure that the imputed data maintains integrity without introducing unrealistic fluctuations.
• Previous Day Imputation
We leverage strong daily patterns by filling in missing values with data from the same time point on the previous day. This method is particularly effective for datasets with strong daily seasonality – when the underlying data is influenced by daily cycles, such as human activity, business hours, or processes that adhere to the day-night cycle. For this imputation, we first identify the start of each missing interval, we then shift the previous data forward or backwards by one day to fill in the gaps. Post-imputation validation ensures that no new, missing or infinite values are introduced, preserving the dataset’s integrity.
• LSTM–Based Imputation
We integrate a Long Short-Term Memory (LSTM) neural network into our imputation workflow to capture complex temporal dependencies and patterns that other methods might miss. LSTM is especially useful for time series data because it can learn long-term dependencies. A comprehensive discussion on LSTM could easily warrant its own post but, for now, it is important to note that while LSTM-based imputation can capture non-linear patterns and improve imputation quality, it is computationally and time expensive to implement. Therefore, we disable the LSTM module when volume of data makes LSTM training and imputation impractical.