It’s been more than nine months since my last blog on PostgreSQL, and we’ve now been using it as a business for over a year. In that time, we’ve continued to discover and make use of some of its more advanced features. We’ve also found that PostgreSQL provides some simple and elegant ways to approach common querying problems which would otherwise require long and unreadable queries – which in my opinion is a recipe for mistakes!
In this blog, I’ll share three shortcuts which I frequently use to solve common query tasks. The methods will be explained using a running example with some relevance to our current work. It’s my hope that the tips in this article will make someone’s life a little easier, and save at least one headache along the way.
Example data and scenario
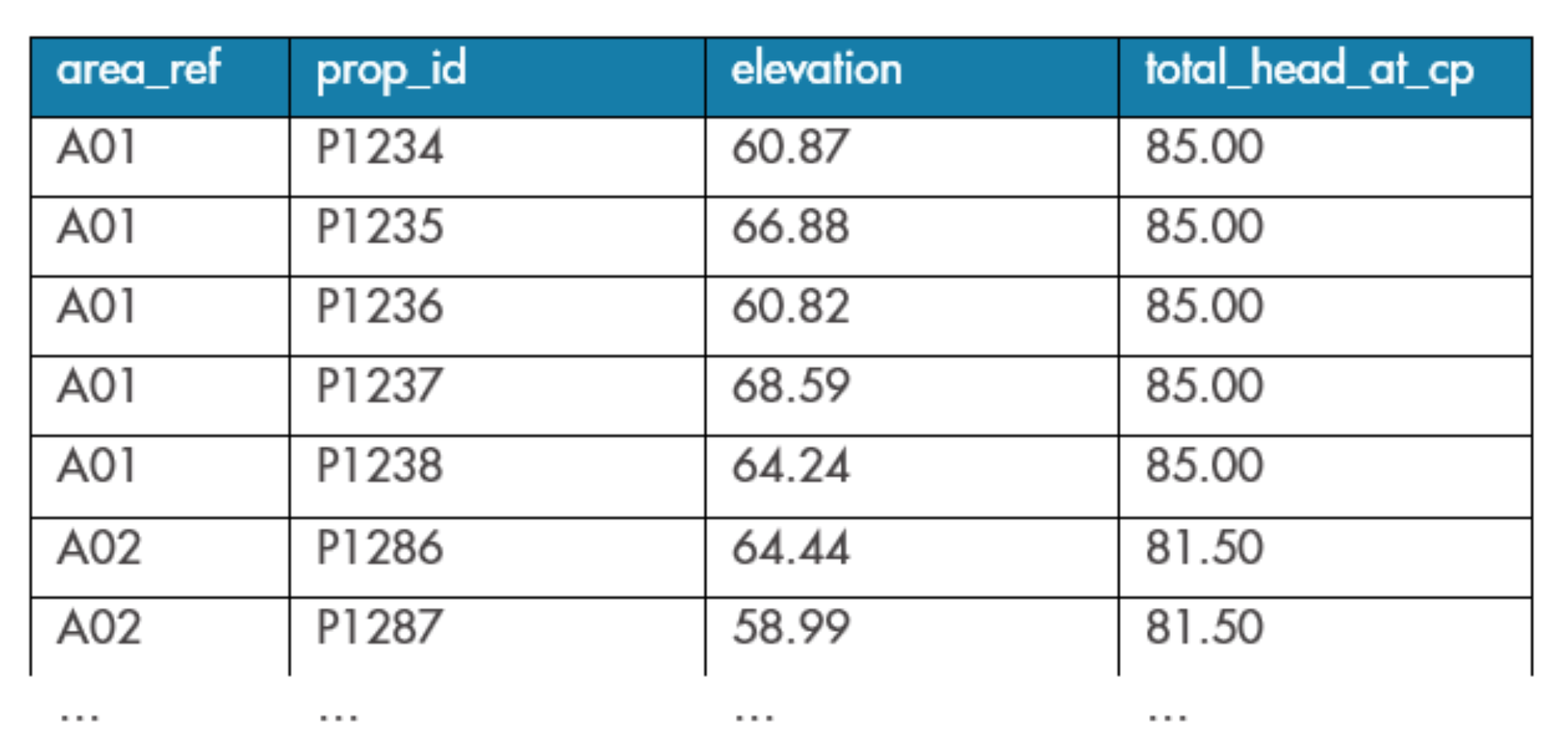
We will use an example scenario where we have some data giving the elevation of 199 properties across three small areas: A01, A02 & A03. We also have a column showing the total pressure head at the critical point of each area. Let’s assume for simplicity that these data sets have already been joined for us to create a prop_data table, as shown in Table 1.
Table 1: Some rows of example data from the head of the prop_data table
Given this data, our task is to quickly interrogate which properties in each area are not receiving at least 15 metres of water pressure. We will refer to these properties as ‘failing’ (i.e. failing to deliver the required pressure level of service).
Tips
Counting with filters
Two obvious questions which we might want to answer to start with are:
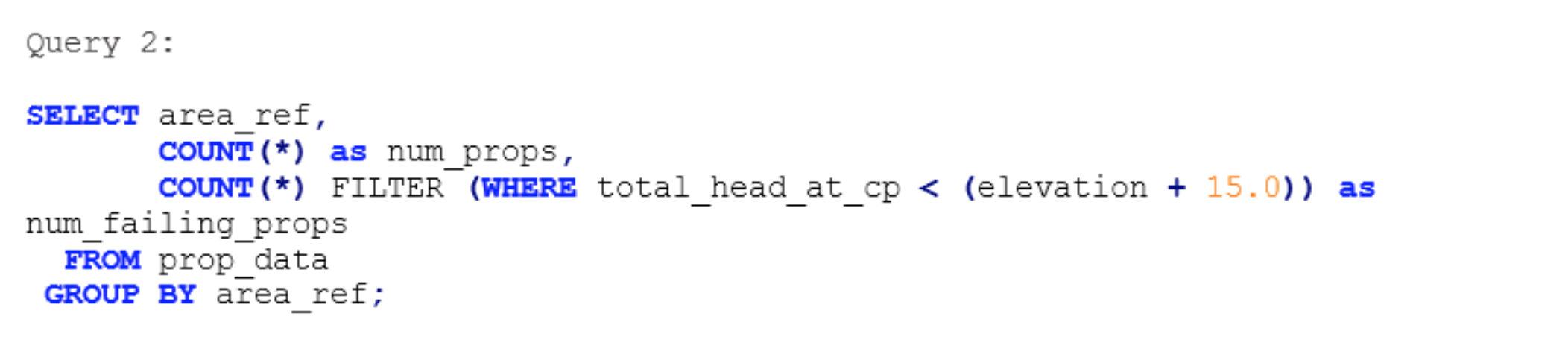
We’ll have to do a COUNT, but did you know that it’s possible to count based on multiple different criteria within a single query? Rather than write a COUNT query and running it several times with different WHERE conditions, we can do:
Thanks to the magic of the FILTER keyword, we’re able to specify the constraints for each respective count in the same line. In fact, we could ask for as many of these columns as we like, each with their own filter conditions. Moreover, FILTER works with any aggregate function so you can do the same thing with SUM, AVG, etc.
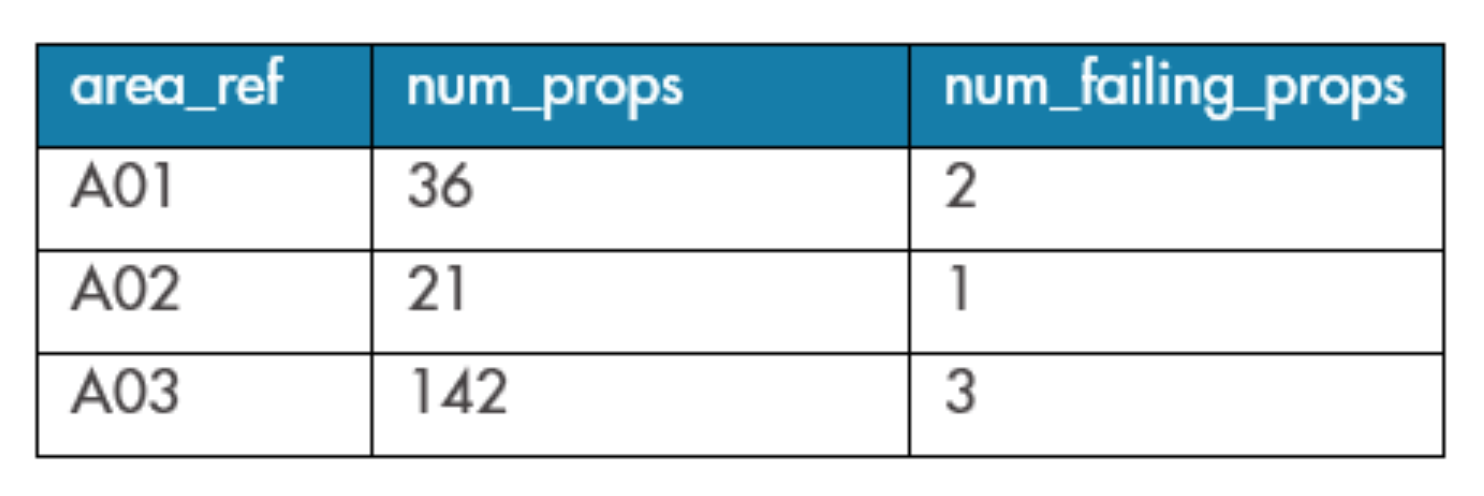
The results of Query 2 are shown in Table 2.
Table 2: Results of COUNT query with multiple constraints
Selecting DISTINCT ON
We’ve confirmed that there are some properties which are failing in each area, and we now want to begin investigating the reason for this. Let’s identify the highest property in each area, and its elevation.
We could use the aggregate function MAX to return each area_ref and the value of its highest elevation. But how do we know which property that is? We would have to run at least one more query, where we ungroup the data again and try to pick out the property having that value for elevation. This seems like a big pain for a question that was so straightforward for us to phrase in English!
Fortunately, PostgreSQL has a gift which can help us avoid having to flick between multiple query windows:
Perhaps, like me, your first reaction is to be confused at the appearance of the DISTINCT keyword here. You might already be familiar with its use to remove duplicate rows. However, when we say SELECT DISTINCT ON (area_ref) we’re asking instead to return only the first record from each (area_ref) group, given the ordering specified on the query.
The first field(s) in the ORDER BY clause should always match those we’re grouping by. Subsequent fields then set the order within the groups. In our case, we’ve sorted by elevation DESC so that the record with the highest elevation appears as the first row in each group.
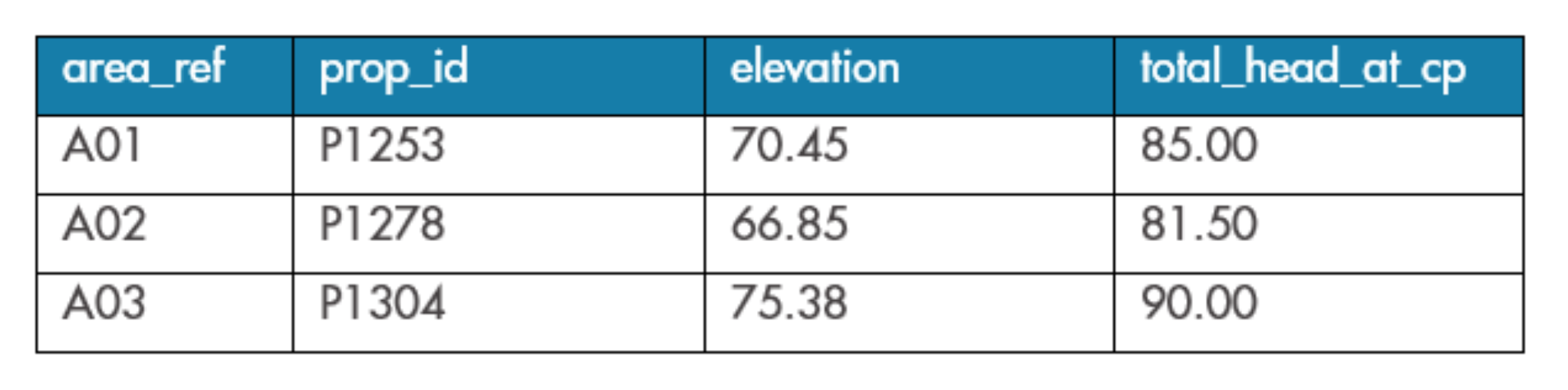
The results of Query 3 are shown in Table 3. We have identified the properties worst-affected by potential pressure deficiency in each area, and quantified that deficiency, within a single, simple query.
TABLE 3: Results of DISTINCT ON query to fetch highest-valued records without losing columns in a GROUP BY
Array aggregation
We can go a step further! Very commonly, I find myself needing to quickly interrogate data by:
Summarising it using aggregation (e.g. by counting the number of failing properties in each area)
Carrying out further investigation (often using another system) on the objects which are counted within each group without losing the context of the initial summary
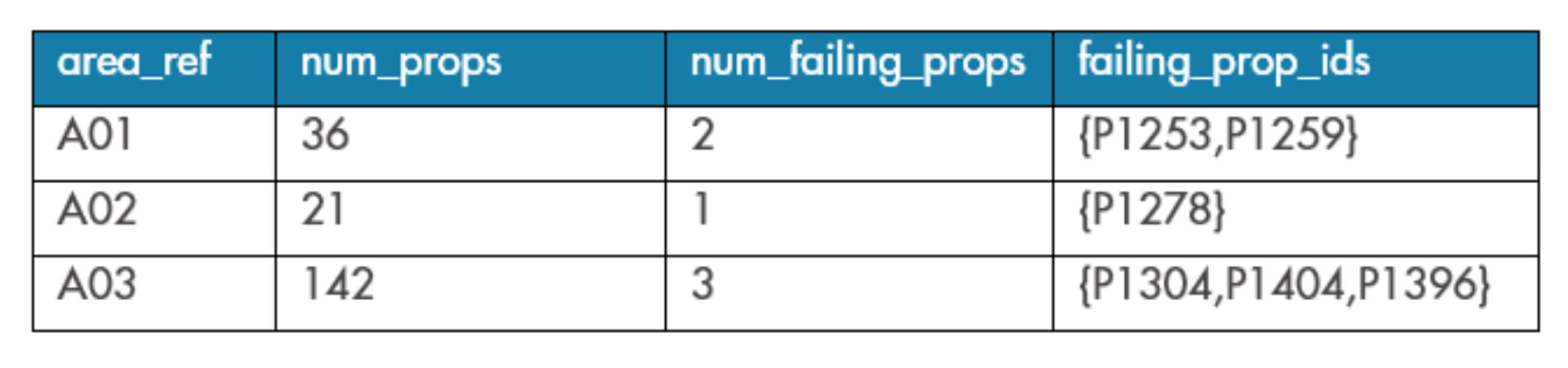
In Query 2, we counted the number of failing properties in each area. We can go a step further and use the ARRAY_AGG function to fetch what’s in those groups without ungrouping.
Consider the following query, which is identical to Query 2 except from the addition of one line:
The results are shown in Table 4. We were able to return the identity of all failing properties as an array alongside the aggregated summary. In this case, the properties in the array are (optionally) ordered by those with the worst pressure deficiency. In terms of our running scenario, we’ve essentially created a ‘leaderboard’ with which we can focus our low pressure investigations. We can now use these results to continue our work, for example, to search for a property in GIS to check whether it might be fed by a booster pump.
Table 4: Results of ARRAY_AGG query to retrieve data from within groups
In conclusion
While we continue to be impressed by PostgreSQL’s advanced features, it also offers some great easy wins. The three tips shared here have already saved me countless times from having to work with messy queries. Wherever you are in your PostgreSQL journey, hopefully they can save you some time and effort too.